Running LLMs locally has changed the rules of the game in the AI world. Resources like Hugging Face with free access to lightweight models democratize LLMs, like Llama. Every user with a modest PC, like a Mac, can run large language models locally and get excellent performance.
This time, we will discuss how to run Llama on a Mac. You’ll learn everything you need about tech specs, preparation, and tools to achieve the best experience while running a model.
Let’s get started!
Things to get started with Llama on your Mac
To run Llama on Mac for tasks like text generation, translation, code debugging, etc., you need at least:
- A Mac M4 (the best option, although other Macs of the M series are also suitable for machine learning)
- 16 GB RAM
- 50 GB of free space in your storage.
Multiple models of Apple devices for personal use, like MacBooks, can run LMMs of different weights. The latest Mac minis are also great at this sort of task.
Yet, the latest Mac M4s are best for this role among different models. They come with 16GB, 24GB, and 32GB RAM configurations, so all the models are suitable for running LLMs.
How to run Llama on Mac?
Starting with Llama on Mac is not a complicated process. All you need to do is set up your tools and choose the model variant you need. That takes up to ten minutes altogether.
LM Studio is the best tool for LLM installation on a Mac. It is free, fast to set up, integrates with Hugging Face, and allows you to run models in a friendly chat interface.
Here are the steps to run Llama on Mac with LM Studio:
- Download LM Studio on your Mac
- Find the Llama model in the list
- Download the selected model
- Load and run the model locally.

Below, we will explain these steps in more detail.
Download LM Studio on your Mac
Running an LLM with LM Studio is simple and requires just a few steps.
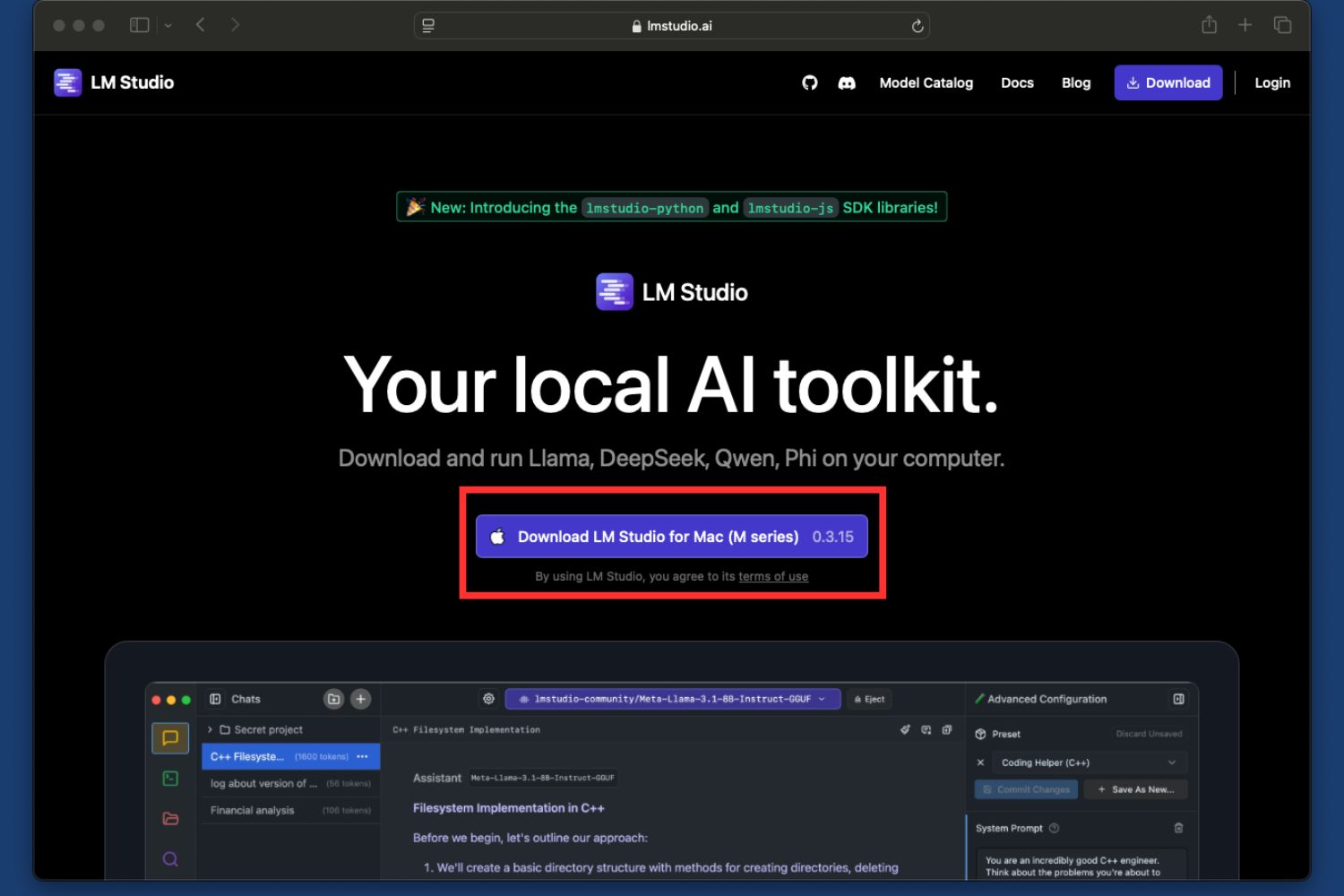
Step 1. Go to the official LM studio website and download the app to your laptop.
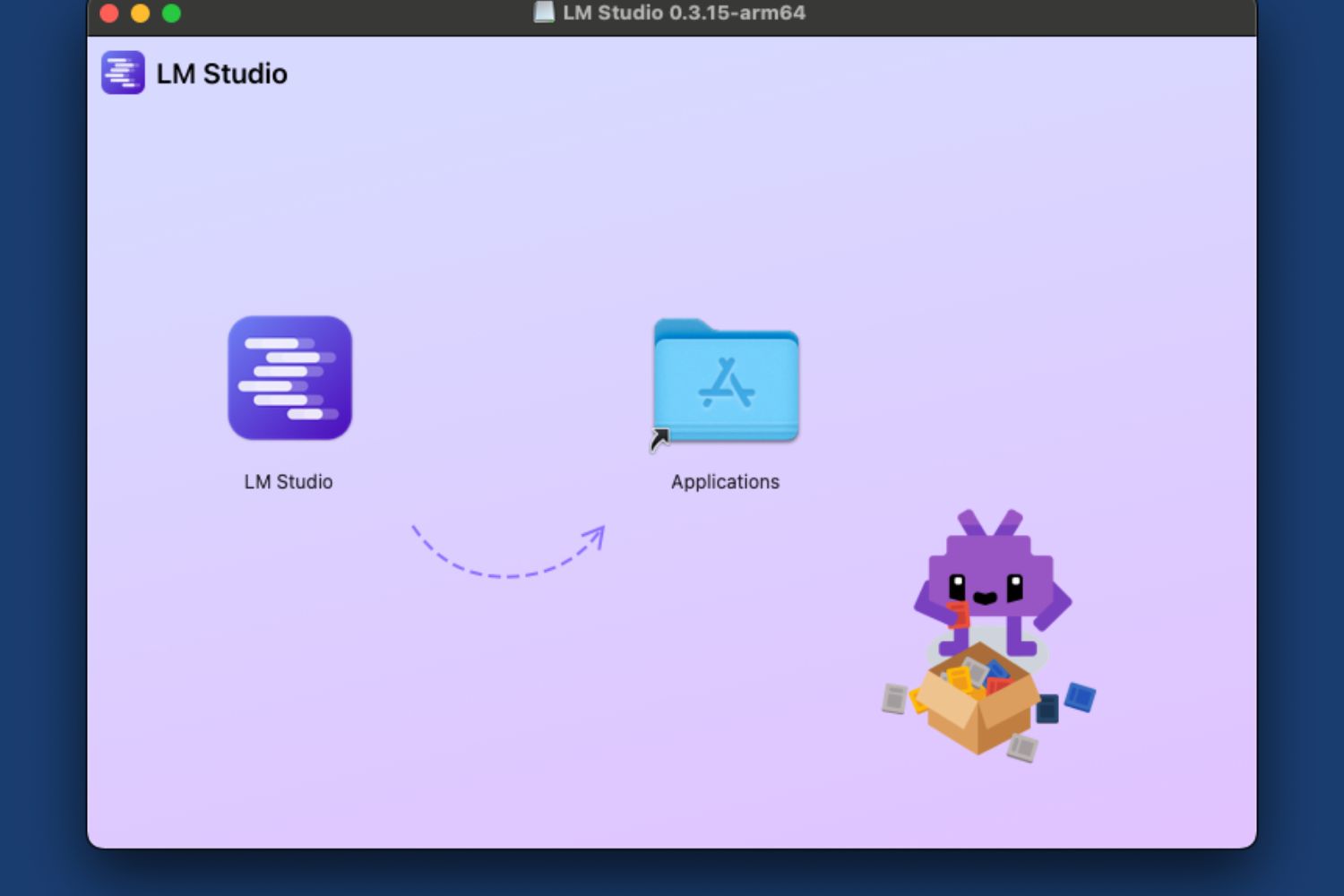
Step 2. As you download it, your Mac will ask you to transfer the app to the Applications folder.
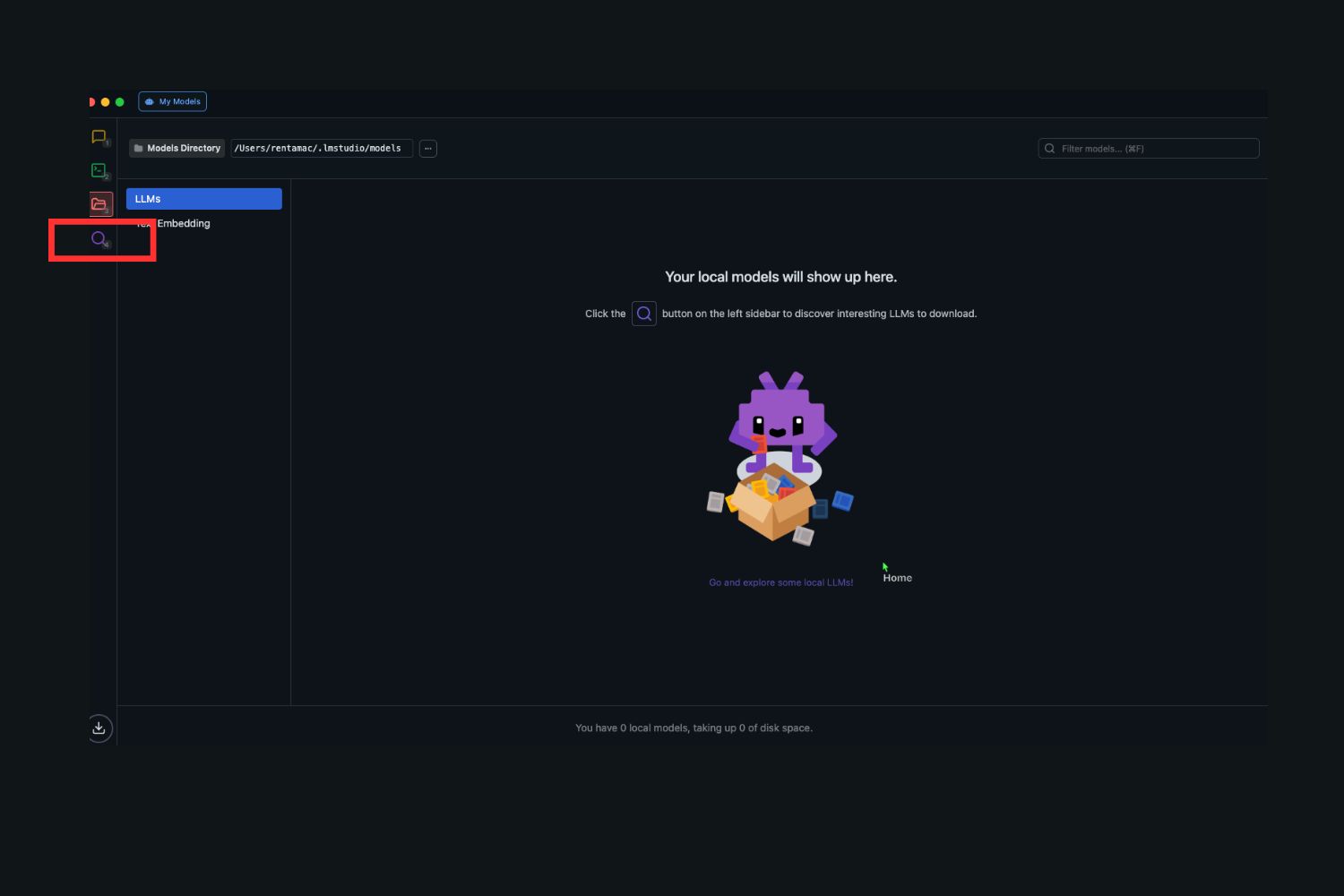
Step 3. Find LM Studio in the Applications folder and run it from there.

Find the Llama model in the list
LM Studio is integrated with Hugging Face so that you can access over 100K Llama models there.
Before you download the model, you must pay attention to its weights. The weights are defined by the number of parameters used by the model. For example, the Llama 3 model has over 70 billion parameters, while the Llama 4 has 17 billion active and 400 billion total parameters.
The number of parameters influences the sophistication of tasks it can handle. Also, it requires a considerable volume of memory to use. This means you can run a classic 70B Llama version from a data center with powerful processors.
But you should use a lighter model if you run it from a Mac. At Hugging Face, you can find models with 7, 8, or 12 billion parameters. There are also smaller ones, but these work great for the solid Mac M4 Llama performance.
Here are the steps to take when finding the Llama model you need in the list:
Step 1. Go to the search.
Step 2. Type the name of the model you need in the search bar.

Step 3. Select the model with the number of parameters you need.

Download the selected model
As you decide on the model you need, press the download button. The Download window will open, showing the status of the process.

Load the model and run it locally
At the last stage of the process, you load the model. After this, the chat interface is launched. There, you can write prompts to your model and get results.

Llama is designated for text-based tasks. It is excellent for text generation, coding assistance, and translations. For developers working across platforms, Llama can complement workflows like Swift development from Windows environments, especially when Mac access is handled virtually.
Why run Llama locally on your computer?
There are multiple reasons to run Llama locally:
- Privacy: A model that runs locally doesn’t share your data with third parties, so it is an excellent choice if you are concerned about privacy.
- Offline access: You can run the downloaded model offline, which means you can use it anywhere.
- Capability: The Llama models are quite capable of the tasks they are designed for, like translation, testing, and code generation.
- Free: you can save your projects, customize them, and get great results without paying for the model’s usage.
Summing up
Mac M4 Llama performance allows using generative AI locally with decent speed and quality. Whether you are using it for research, coding assistance, or personal projects, you may enjoy the capability of cutting-edge technology while caring for your privacy.
Want to run Llama but lack a powerful Mac?
Rent the latest Mac models remotely at rentamac.io to access the computing power needed to enjoy the benefits of running LLMs locally!